
Versie 1.0 (31/12/2025) van het corpus bevat 6,2 miljoen tokens (woorden) en 176 uur aan (onbewerkte) audiofragmenten, verspreid over honderden dialecten in het Limburgse taalgebied. De documentatie van de metadata vindt u terug op GitHub voor het openbaar gedeelte en in het toegangsportaal voor het volledige corpus.
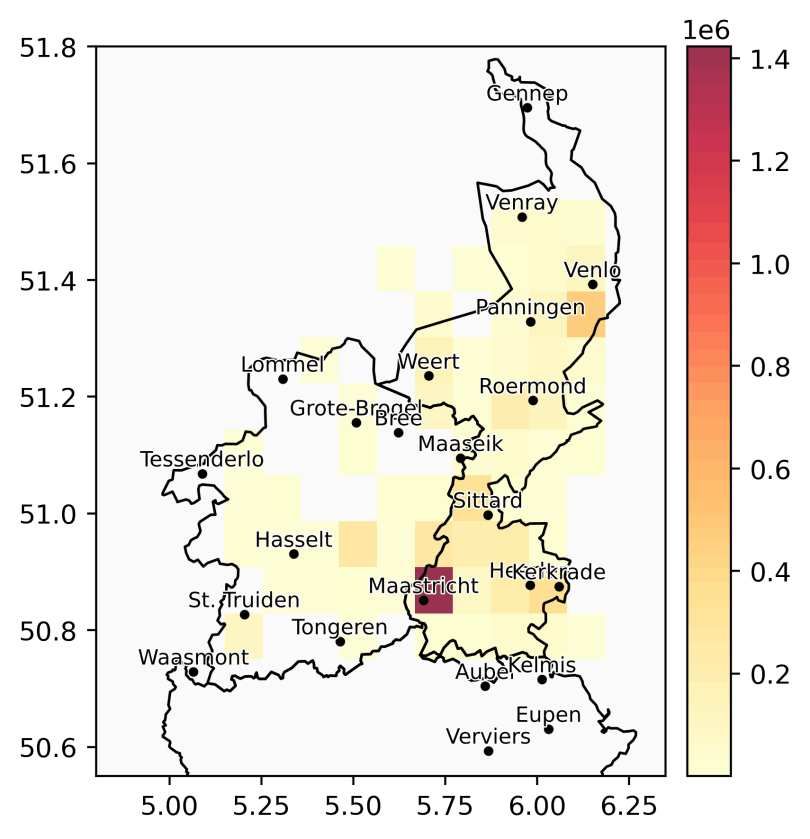
Tokens (woorden) in het corpus (in miljoen)
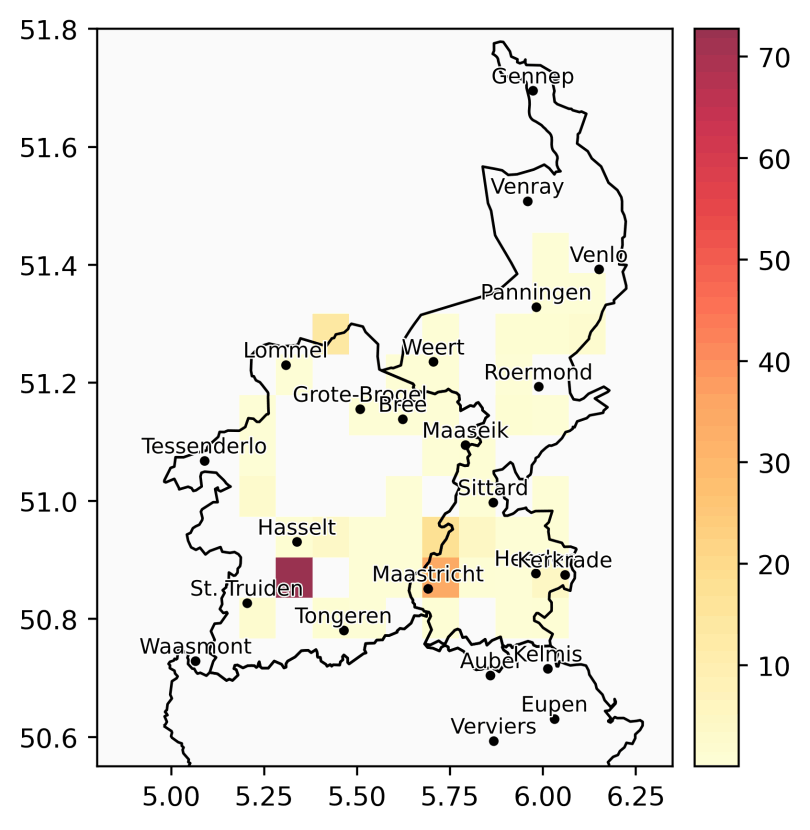
Audiofragmenten in het corpus (in uur)
Het Limburgs Corpus is toegankelijk gemaakt voor verschillende doeleinden. Het openbaar gedeelte van het corpus kan u vrij inkijken en gebruiken, u dient wel rekening te houden met de nodige auteursrechtenlicenties.
De overgrote meerderheid van het corpus is momenteel enkel toegankelijk voor wetenschappelijke doeleinden en kan u enkel inkijken en gebruiken als u een onderzoeker bent verbonden aan een academische instelling. We werken er hard aan om het "wetenschappelijk" gedeelte zo snel mogelijk voor iedereen te ontsluiten.
Opgelet: Aan ieder bestand is een licentie verbonden, deze bepaalt hoe u de bestanden mag gebruiken en wie u moet citeren als u ze gebruikt of reproduceert. Alle licenties zijn Creative Commons licenties.
Gelieve strikt de voorwaarden voor wetenschappelijk gebruik omtrent autersrechten en Artificiële Intelligentie te respecteren (Engels).